Crawling
크롤링(Crawling)이란 검색 엔진과 같은 프로그램이 웹을 탐색하며 웹 페이지의 정보를 수집하는 과정을 의미한다. 크롤러가 이러한 작업을 수행하는데, 찾은 페이지로부터 텍스트, 이미지, 동영상을 다운로드 한다. 수집된 데이터는 검색 엔진의 인덱스에 저장되며, 사용자의 검색 쿼리에 따라 검색 결과로 제공된다.
스크래핑과 유사하지만 목적에 다소 차이가 있다. 크롤링이 공개된 대규모의 웹사이트의 내용을 수집하고 인덱싱하기 위함이라면, 스크래핑은 특정 웹사이트의 데이터를 저장하는 목적이다.
크롤링 시스템 구조
Google에는 다양한 크롤러가 있다. 데스크톱 사용자와 모바일 사용자를 시뮬레이션하는 일반 크롤러를 Googlebot 이라고 하는데, 이를 예시로 설명하면 다음과 같다.

- Googlebot은 페이지를 Crawl Queue와 Render Queue에 추가한다. Crawl Queue에는 크롤러가 방문한 모든 웹사이트가 담겨있다.
- Crawl Queue에서 URL을 가져올 때는 크롤링이 허용되는지 먼저 확인한다. 이때,
robots.txt파일을 읽고, URL이 허용되어 있지 않으면 HTTP 요청을 건너뛴다. - 허용되는 경우, Googlebot은 HTML 링크의
href속성에 있는 다른 URL에 관한 응답을 파싱하고 Crawl Queue에 이러한 URL을 추가한다. Googlebot은 JavaScript를 직접 실행할 수 있지만, 추가적인 JavaScript 실행을 필요로 하는 웹사이트의 경우, Render Queue에 추가해 리소스를 가져온다. - Render Queue에는 웹사이트가 렌더링 되기 위해 필요한 리소스를 담게 되는데, 리소스를 가져올 때마다 Renderer가 JavaScript를 실행한다.
- 참고로, 크롤링을 원치 않는 경우, HTML 내에서 페이지 수준을 직접 설정할 수 있는데,
<meta name="robots" content="noindex">라고 명시되어 있지 않은 한 Googlebot은 모든 페이지를 Render Queue에 추가한다.
- 참고로, 크롤링을 원치 않는 경우, HTML 내에서 페이지 수준을 직접 설정할 수 있는데,
- 이때, Renderer는 Headless Chromium 브라우저인데, 웹사이트를 렌더링하기 위해 필요한 JavaScript를 실행하는 역할을 한다.
- Googlebot은 렌더링된 HTML을 다시 파싱하고, 이때 발견되는 URL들은 Crawl Queue에 추가한다.
- Google은 또한 렌더링된 HTML을 사용하여 페이지의 색인을 생성한다.
크롤링 방법
정해진 것은 없지만, 가령 일반 크롤러같은 경우, Queue(FIFO, First In First Out)를 활용한 BFS(Breadth First Search) 방식으로 웹사이트를 찾을 수 있다.
만약 Stack(LIFO, Last In First Out)구조의 DFS(Depth First Search)로 웹사이트를 검색한다면, 잘못된 edge의 Spatial proximity에 빠져 제대로된 검색이 안 될 수 있다.
크롤링 특징
최신성(Freshness)
웹은 매우 동적이기 때문에, 수집된 페이지가 얼마나 최신인지(수정 또는 삭제 됐는지에 대해) 지속적으로 확인이 필요하다.
1.4.1 J. Cho와 H. Garcia-Molina의 실험 (Effective Page Refresh Policies For Web Crawlers)
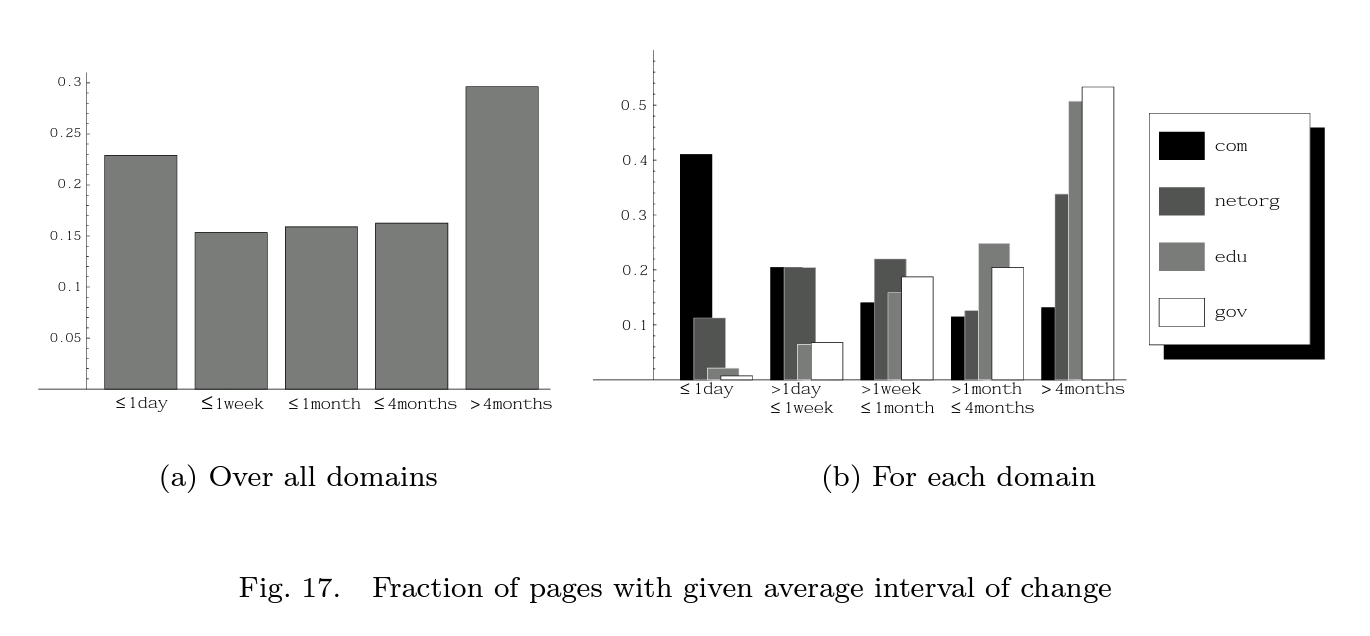
- 270개의 유명 웹사이트로부터, 크롤러가 처음 수집하는 3,000개의 URL로부터 데이터를 추출해 페이지 순위를 비교했다.
- (a)결과 - 모든 도메인 중 20% 이상이 방문할 때마다 페이지가 변경되어 있었다.
- (b)결과 -
.com사이트 중 40% 이상이 매일 페이지가 변경되었다. - 이를 참고해 너무 많이 변경되는 경우 또 다시 크롤링할 가능성이 있기 때문에, 순위에 일종의 패널티를 두어, 너무 자주 방문하지 않도록 할 필요가 있어보인다.
범위(Coverage)
얼마큼의 범위에 해당하는 웹사이트를 수집하고, 인덱싱 해야하는지에 대한 정도이다. 웹의 무한함을 고려하면, 모든 웹사이트에 대해 100% coverage를 제공하는 것이 아니라, 웹의 중요한 부분을 얼마나 "cover"했는지를 보는 것이 중요하다. 동일 다운로드 또는 요청 수 대비 중요한 페이지를 일찍 "cover"하기 위해서는 페이지의 중요도를 알 필요가 있다.
이에 Google에서는 PageRank 지표를 활용하는데, 잘못된 정보를 제거할 필요가 있는데, 이로써 E-A-T(Expertise, Authoritativeness, and Trustworthiness) 를 활용한다. Google에서도 이를 Ranking Factor로 시인했다.